Flink源码解析(二)——Flink流计算应用执行环境解析
在Flink应用执行过程中会涉及到3个主要的执行环境变量,分别为StreamExecutionEnvironment、Environment、RuntimeContext。它们的作用层次、作用时机、作用范围各不相同。3种环境对象的关系如下图:
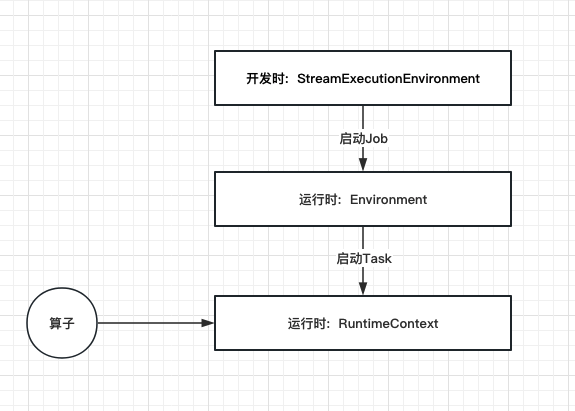
下面分别介绍3种环境对象的细节信息。
一、StreamExecutionEnvironment解析
StreamExecutionEnvironment是Flink应用开发时的概念,表示流计算作业的执行环境。它是应用开发配置、属性设置的起点,数据源生成的接口,作业开始执行的入口、并负责创建不同类型的执行环境。下面对这四个方面展示源码的实现逻辑。
1、开发配置及属性设置
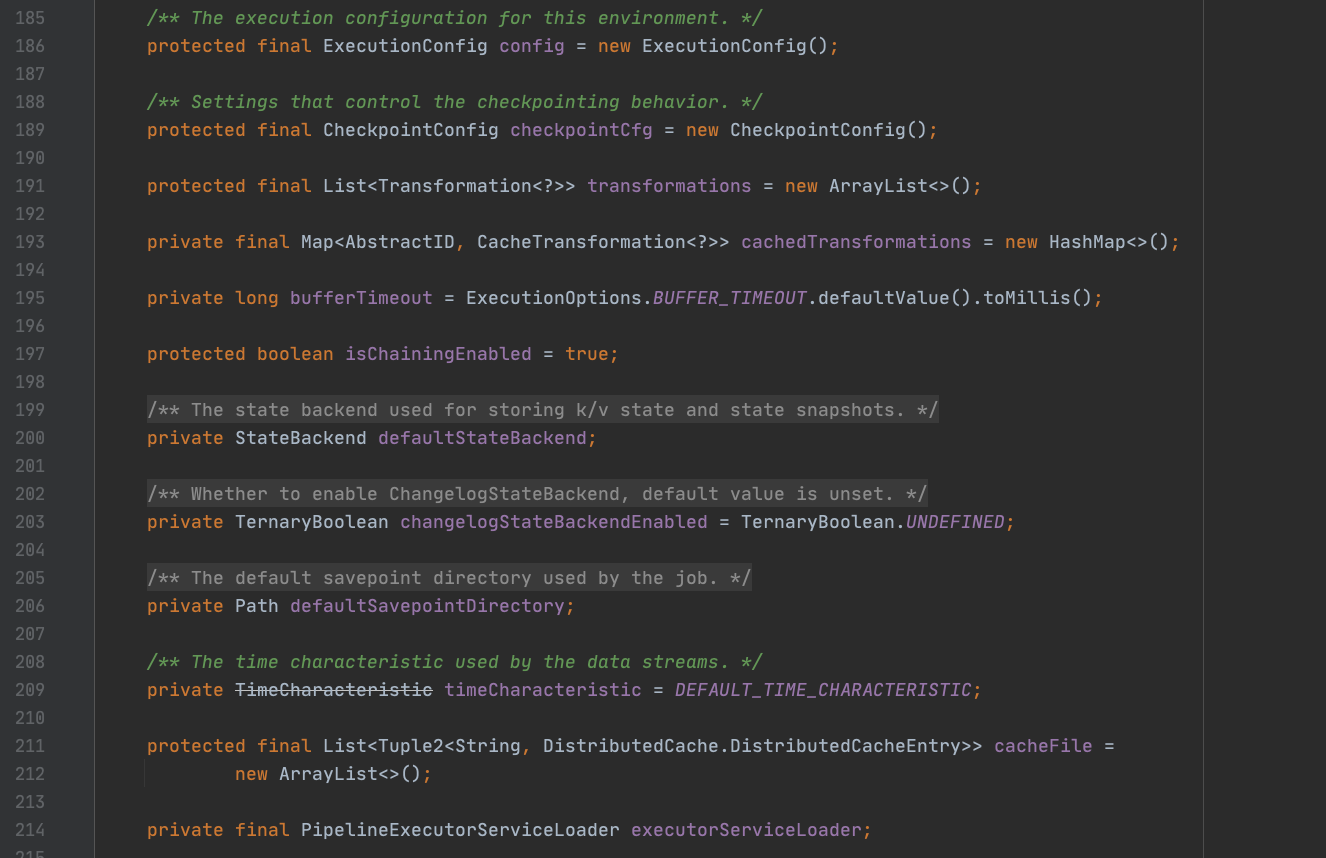

(1).当前StreamExecutionEnvironment配置对象并未统一,config负责环境的执行配置,checkpointCfg配置负责控制checkpointing行为,长期来看DataStream相关的api配置会统一添加至configuration配置变量中。
(2).transformations集合负责存储DataStream api转化而来的transformation。类似map、flatmap、filter等api入参Funtion变量会设置到AbstractUdfStreamOperator算子类的userFunction变量中,进而转化生成一个个Transformation并添加到transformations集合中。后续随笔会着重讲解api转化为Transformation过程。
(3).bufferTimeout代表输出buffer的刷新时间。
(4).isChainingEnabled代表合成算子链开关。上下游有条件chaining的算子合成算子链后会优化程序的执行性能。
(5).defaultStateBackend状态后端变量,和状态保存有关。
(6).timeCharacteristic流计算应用的时间语义。
(7).slotSharingGroupResources槽位共享组的资源概况。
2、数据源生成接口
(1).从内存中读取数据
public DataStreamSource<Long> fromSequence(long from, long to);
public final <OUT> DataStreamSource<OUT> fromElements(OUT... data);
public final <OUT> DataStreamSource<OUT> fromElements(Class<OUT> type, OUT... data);
public <OUT> DataStreamSource<OUT> fromCollection(Collection<OUT> data);
public <OUT> DataStreamSource<OUT> fromCollection(Collection<OUT> data, TypeInformation<OUT> typeInfo);
public <OUT> DataStreamSource<OUT> fromCollection(Iterator<OUT> data, Class<OUT> type);
public <OUT> DataStreamSource<OUT> fromCollection(Iterator<OUT> data, TypeInformation<OUT> typeInfo);
public <OUT> DataStreamSource<OUT> fromParallelCollection(SplittableIterator<OUT> iterator, Class<OUT> type);
public <OUT> DataStreamSource<OUT> fromParallelCollection(SplittableIterator<OUT> iterator, TypeInformation<OUT> typeInfo);
(2).从文件读取数据
当前readFile()文件读取api已是deprecated状态,推荐尝试FileSource文件数据源类的forRecordStreamFormat()、forBulkFileFormat()、forRecordFileFormat()方法。
(3).从socket读取数据
public DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter, long maxRetry);
入参分别代表主机名、端口号、数据分隔符、最大重试次数
(4).自定义读取数据
private <OUT> DataStreamSource<OUT> createInput(InputFormat<OUT, ?> inputFormat, TypeInformation<OUT> typeInfo, String sourceName);
private <OUT> DataStreamSource<OUT> createFileInput(inputFormat,typeInfo,sourceName,monitoringMode,interval);
private <OUT> DataStreamSource<OUT> addSource(function,sourceName,typeInfo,boundedness);
public <OUT> DataStreamSource<OUT> fromSource(source,timestampsAndWatermarks,sourceName,typeInfo);
其中fromSource方法适配flink新数据源架构的使用方法。
3、执行入口
public JobExecutionResult execute();
execute方法是流计算应用的执行入口,业务逻辑编写完成后调用execute方法才会触发程序的执行。该方法在应用提交阶段时主要负责创建StreamGraph、JobGraph、ExecutionGraph等数据结构,最后经过Flink的调度组件在集群中启动计算任务。Graph的转换过程是DataStream api转换为Transformation,进而经过StreamGraph->JobGraph->ExecutionGraph及调度执行计算Task等。后续随笔会详细讲解各个环节的转换细节。
4、不同类型执行环境
getExecutionEnvironment();
createLocalEnvironment();
createLocalEnvironmentWithWebUI();
createRemoteEnvironment();
以上方法主要创建StreamExecutionEnvironment、LocalStreamEnvironment、RemoteStreamEnvironment、StreamContextEnvironment、StreamPlanEnvironment等不同类型的执行环境。
基本工作流程如下:执行Flink作业Main方法生成StreamGraph、JobGraph,设置任务配置信息、提交JobGraph到Flink集群开始调度执行。
二、Environment解析
Environment代表Flink运行时环境,该接口定义了运行时刻Task的配置信息。主要实现类有RuntimeEnvironment和SavepointEnvironment。
//Task.java
doRun(){...}
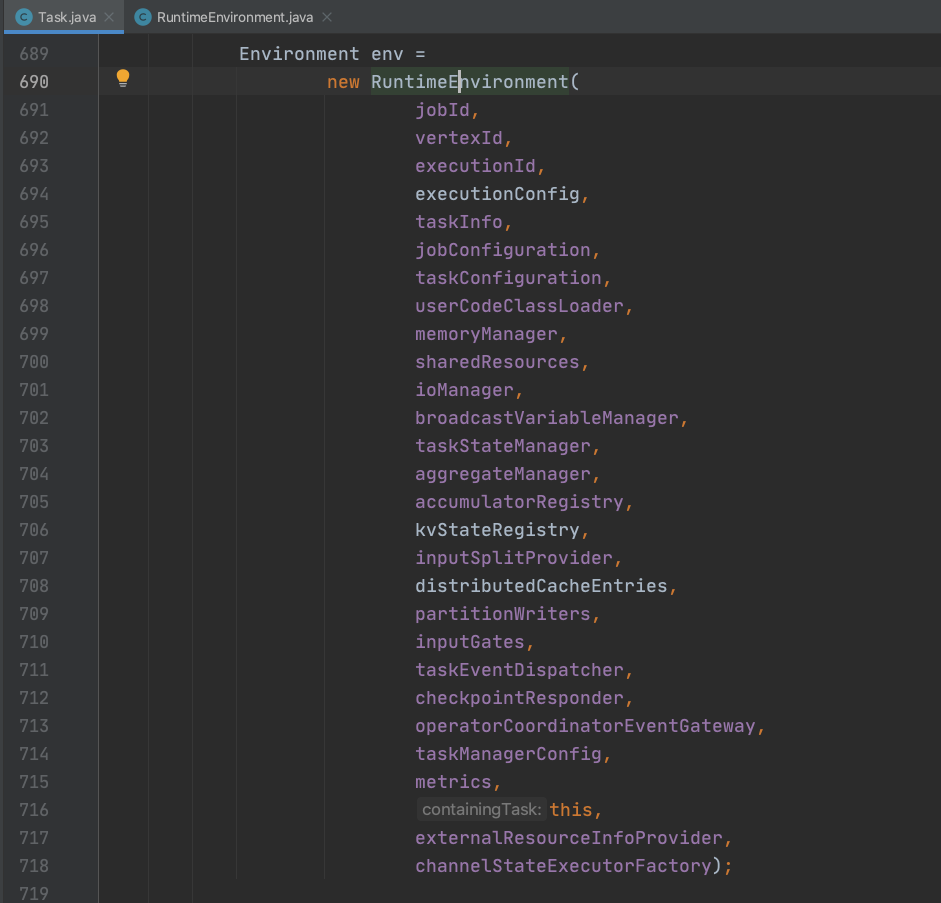
包含Task执行需要的核心组件MemoryManager、IOManager、BroadcastVariableManager、TaskStateManager、InputSplitProvider、TaskEventDispatcher等。
三、RuntimeContext解析
RuntimeContext是Function运行时上下文,封装了Function运行时需要的所有信息,如并行度信息、Task名称、ExecutionConfig、State等。在RichFunction中通过getRuntimeContext()方法可以获取该对象,进而执行状态操作等行为。其主要的实现类有StreamingRuntimeContext、SavepointRuntimeContext等。