CUDA入门笔记
硬件概念:
一个SM(Streaming Multiprocessor)中的所有SP(Streaming Processor)是分成Warp的,共享同一个Memory和Instruction Unit(指令单元)。
从硬件角度讲,一个GPU由多个SM组成(当然还有其他部分),一个SM包含有多个SP(以及还有寄存器资源,Shared Memory资源,L1cache,Scheduler,SPU,LD/ST单元等等)
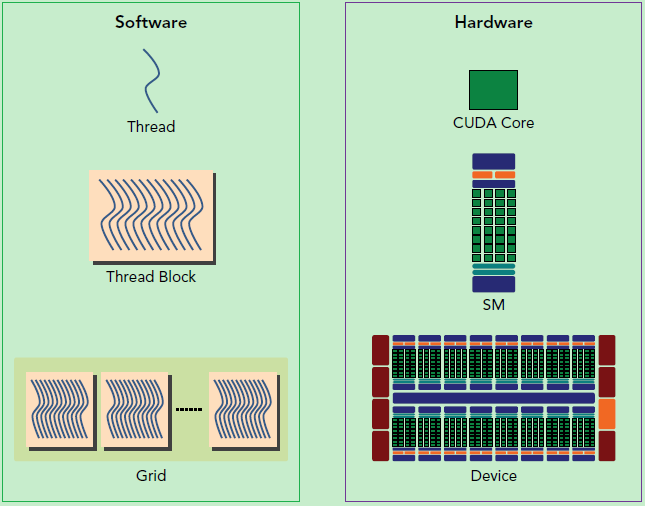
SM采用的是SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(warps),线程束包含32个线程.
线程数尽量为32的倍数,因为线程束(Warp)共享一个内存和指令。假如线程数是1,则Warp会生成一个掩码,当一个指令控制器对一个Warp单位的线程发送指令时,32个线程中只有一个线程在真正执行,其他31个进程会进入静默状态。
了解硬件的代码:
cu文件:
#include <iostream>
#include "cuda_runtime.h"
int main() {
int dev = 0;
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, dev);
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "每个SM的最大 线程 数:" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个SM的最大 线程束 数——Warp数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
return 0;
}CMakeLists:
cmake_minimum_required(VERSION 3.8)
project(CUDA_TEST)
find_package(CUDA REQUIRED)
message(STATUS "cuda version: " ${CUDA_VERSION_STRING})
include_directories(${CUDA_INCLUDE_DIRS})
cuda_add_executable(cuda_test src/test001.cu)
target_link_libraries(cuda_test ${CUDA_LIBRARIES})软件概念
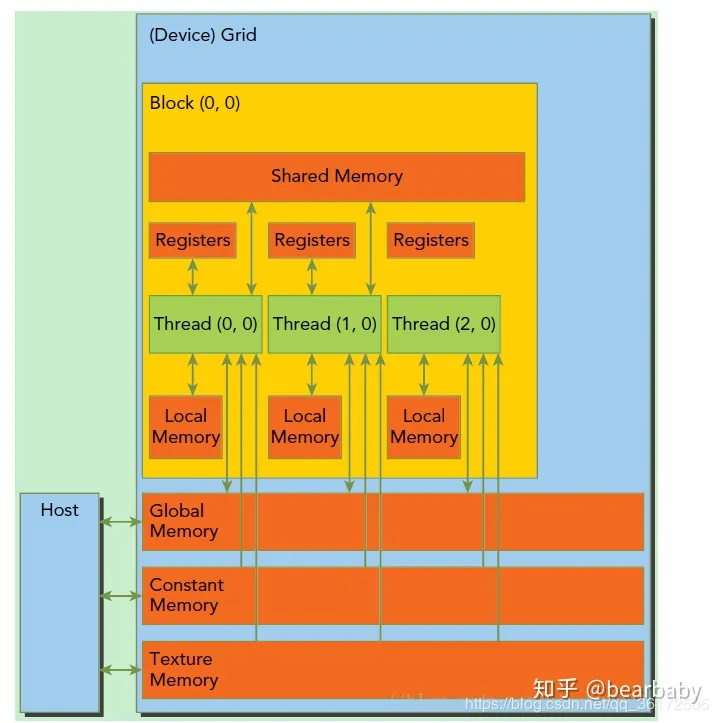
在利用cuda进行编程时,一个grid分为多个block,而一个block分为多个thread
- 每个 thread 都有自己的一份 register 和 local memory 的空间。
- 一组thread构成一个 block,这些thread 则共享有一份shared memory。
- 所有的 thread(包括不同 block 的 thread)都共享一份global memory、constant memory、和 texture memory。
- 不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
- 每一个时钟周期内,warp(一个block里面一起运行的thread,其中各个线程对应的数据资源不同(指令相同但是数据不同)包含的thread数量是有限的,现在的规定是32个。一个block中含有16个warp。所以一个block中最多含有512个线程,每次Device(就是显卡)只处理一个grid。
- 一个sm只会执行一个block里的warp,当该block里warp执行完才会执行其他block里的warp。